Abstract
Speechreading is the task of inferring phonetic information from visually observed articulatory facial movements, and is a notoriously difficult task for humans to perform. In this paper we present an end-to-end model based on a convolutional neural network (CNN) for generating an intelligible and natural-sounding acoustic speech signal from silent video frames of a speaking person.We train our model on speakers from the GRID and TCD-TIMIT datasets, and evaluate the quality and intelligibility of reconstructed speech using common objective measurements. We show that speech predictions from the proposed model attain scores which indicate significantly improved quality over existing models. In addition, we show promising results towards reconstructing speech from an unconstrained dictionary.
ICCVW 2017 - Improved Speech Reconstruction from Silent Video




Supplementary video
The following video contains a few examples of silent video frames given to our model as input, along with the acoustic signal generated by the system. The first two examples are of Speaker 3 (S3) and Speaker 4 (S4) from the GRID corpus. Separate models were trained on 80% of the data from each speaker, and the training set contained all words present in the testing set.The third example is of Lipspeaker 3 from the TCD-TIMIT dataset. In this experiment, training and testing sets contained many different words, such that the predicted speech presented here shows significant progress towards learning to reconstruct words from an unconstrained dictionary.
BibTeX
@article{ephrat2017improved,
title={Improved Speech Reconstruction from Silent Video},
author={Ephrat, Ariel and Halperin, Tavi and Peleg, Shmuel},
journal={ICCV 2017 Workshop on Computer Vision for Audio-Visual Media},
year={2017}
}
Code
Code for this work is being prepared for release. In the meantime, code for our ICASSP 2017 paper can be found here. Enjoy!ICASSP 2017 - Vid2Speech: Speech Reconstruction from Silent Video

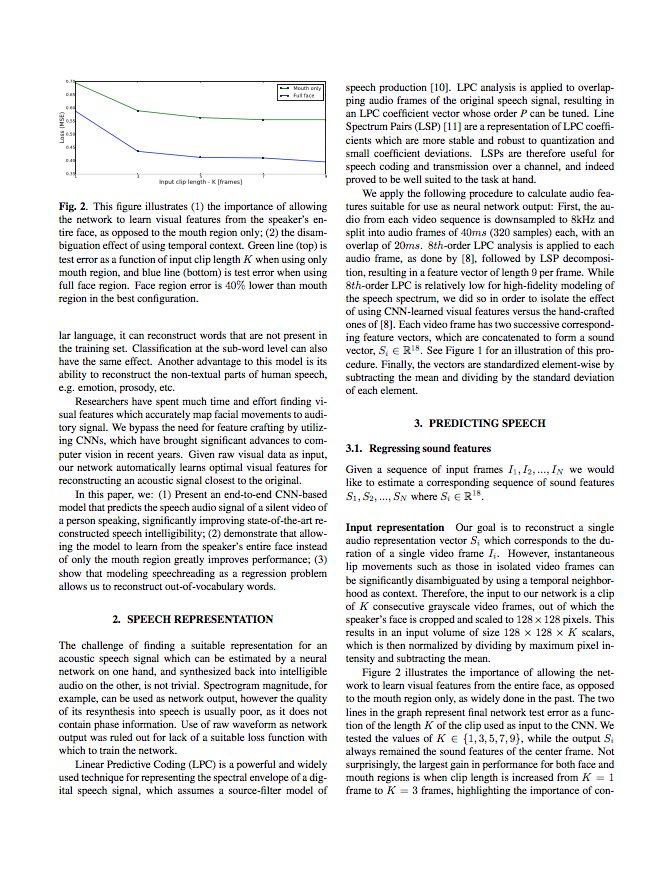



Samples of Reconstructed Speech
The following videos consist of original video frames given to our CNN as input, along with the acoustic signal generated by the system. We performed a human listening test using Amazon Mechanical Turk workers in order to evaluate the reconstructed speech intelligibility. Presented here are two examples from each transcription task given to MTurk workers.Reconstruction from full dataset
For this task we trained our model on a random 80/20 train/test split of the 1000 videos of Speaker 2 (S2) and Speaker 4 (S4) from the GRID corpus, and made sure that all 51 GRID words were represented in each set.S2
S4
Reconstructing out-of-vocabulary (OOV) words
In this task, the videos in our dataset were sorted according to the digit (fifth word) uttered in each sentence, and our network was trained and tested on five different train/test splits - each with two distinct digits left out of the training set. For example, for the following video on the left side, the network was trained on all videos with the numbers 3,4,..,9,0 uttered, and tested only on the ones containing the numbers 1 and 2.For the left video, correct digit is "2", and the right is "7".
BibTeX
@inproceedings{ephrat2017vid2speech,
title = {Vid2Speech: speech reconstruction from silent video},
author = {Ariel Ephrat and Shmuel Peleg},
booktitle = {2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = {2017},
organization = {IEEE}
}