The single image animation primitives were created by Jonathan Reich jonathanreichandco@gmail.com
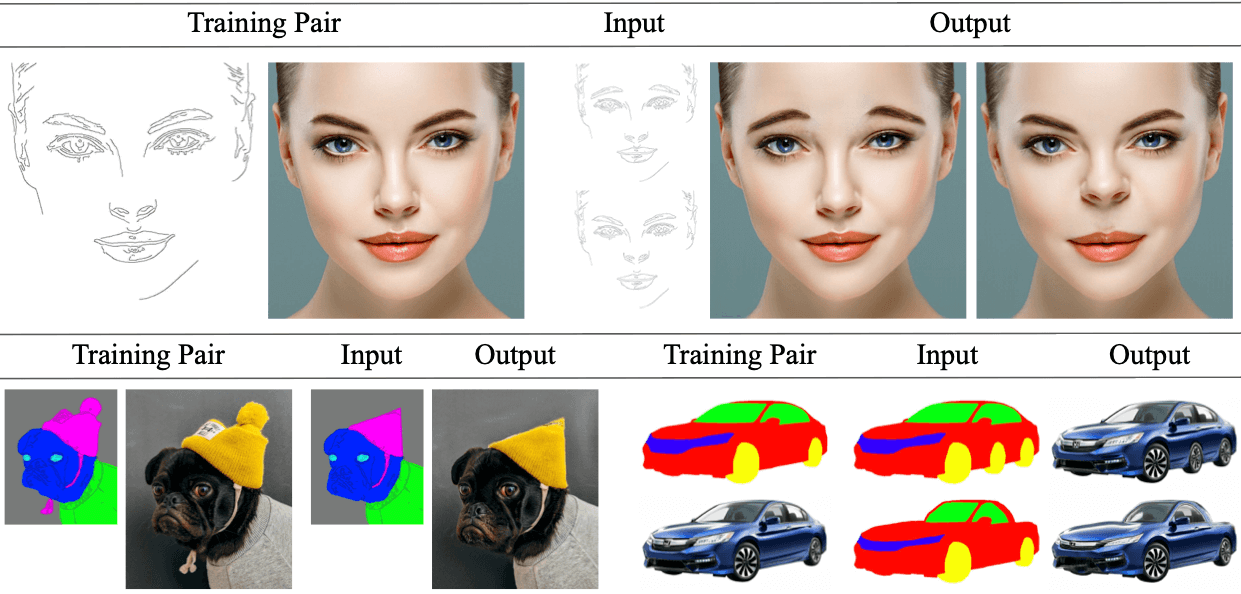
DeepSIM was trained on a single training pair, shown to the left of each sample. First row "face" output- (left) flipping eyebrows, (right) lifting nose. Second row "dog" output- changing shape of dog's hat, removing ribbon, and making face longer. Second row "car" output- (top) adding wheel, (bottom) conversion to sports car.
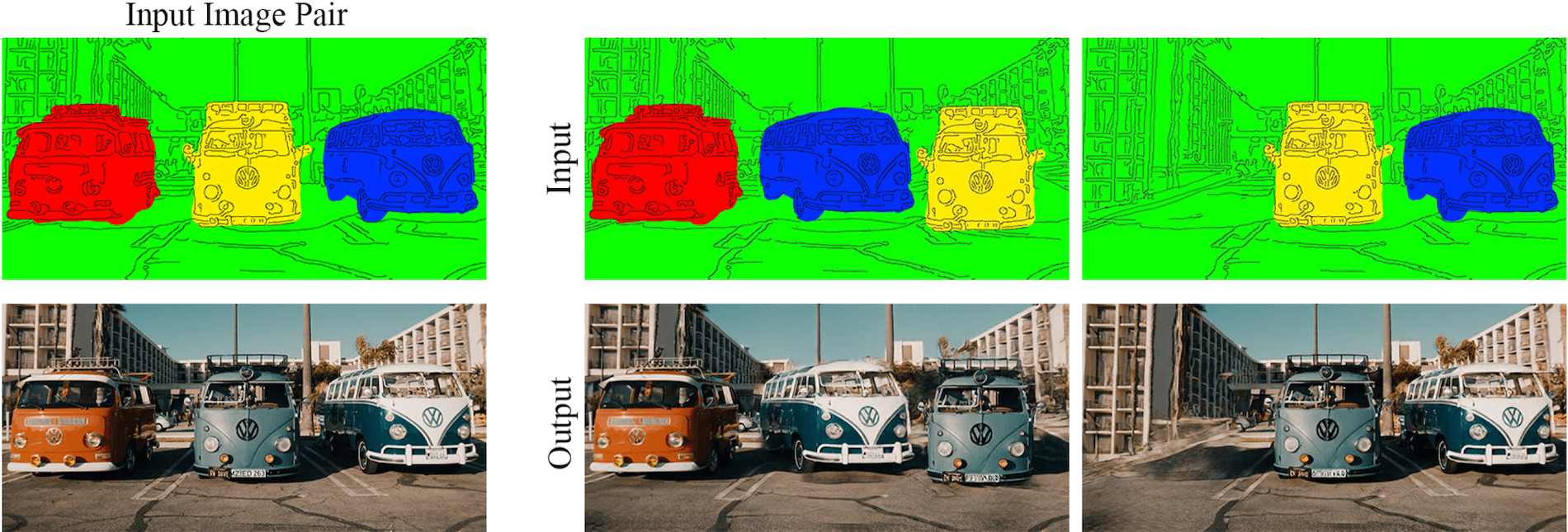
Top row - primitive images. Left - original pair used for training. Center- switching the positions between the two rightmost cars. Right- removing the leftmost car and inpainting the background.

The leftmost column shows the source image, then each column demonstrate the result of our model when trained on the specified primitive. We manipulated the image primitives, adding a right eye, changing the point of view and shortening the beak. Our results are presented next to each manipulated primitive. The combined primitive performed best on high-level changes (e.g. the eye), and low-level changes (e.g. the background).
